如何在本地搭建Spark的调试环境(以IDEA为例) |
您所在的位置:网站首页 › idea spark › 如何在本地搭建Spark的调试环境(以IDEA为例) |
如何在本地搭建Spark的调试环境(以IDEA为例)
|
案例 下面为您介绍一些具体案例。 案例一:SparkPi该案例介绍如何使用Spark计算Pi的粗略值。 创建测试用例SparkPi.scala。 import org.apache.spark.sql.SparkSession import scala.math.random object SparkPi { def main(args: Array[String]): Unit = { val spark = SparkSession.builder .appName("Spark Pi") .master("local[4]") .getOrCreate() val slices = if (args.length > 0) args(0).toInt else 2 val n = math.min(100000L * slices, Int.MaxValue).toInt // avoid overflow val count = spark.sparkContext.parallelize(1 until n, slices).map { i => val x = random * 2 - 1 val y = random * 2 - 1 if (x * x + y * y (x, 1)) .reduceByKey(_ + _) .saveAsTextFile(outputPath) spark.stop() } } 说明运行代码示例前必须先配置环境变量。关于如何配置环境变量,请参见配置环境变量。 需要配置以下参数: sparkMaster:本地运行可配置local[4],集群运行时需配置成yarn-client或yarn-cluster。 ossAccessKeyId:访问OSS所需的AccessKey ID。 ossAccessKeySecret:访问OSS所需的AccessKey Secret。 ossEndpoint:访问OSS所需的Endpoint。 inputPath:wordCount输入文件。 outputPath:wordCount输出文件。 运行main,运行成功后,在OSS控制台查看outputPath下是否有输出文件。  案例三:Spark连接DLF 案例三:Spark连接DLF该案例介绍如何使用Spark连接阿里云DLF,读写数据库表。 在pom.xml中添加metastore-client相关的依赖。 com.aliyun.datalake metastore-client-hive2 0.2.14引入Hive相关依赖。 在集群如下位置下载该部分依赖的JAR包。 $SPARK_HOME/jars/hive-common-x.x.x.jar $SPARK_HOME/jars/hive-exec-x.x.x-core.jar在IDEA的File > Project Structure > Modules页面,导入刚刚下载的JAR包。 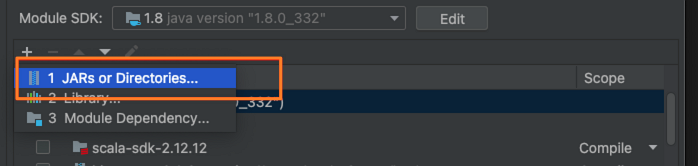 创建测试用例SparkDLF.scala。 import org.apache.spark.sql.SparkSession object SparkDLF { def main(args: Array[String]): Unit = { val sparkMaster = "local[4]" val dlfCatalogAccessKeyId = System.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID") val dlfCatalogAccessKeySecret = System.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET") val dlfCatalogEndpoint = "xxx" val dlfCatalogId = "xxx" val warehouseDir = "/tmp/warehouse" val spark = SparkSession.builder() .appName("Spark DLF Example") .master(sparkMaster) .config("spark.hadoop.hive.imetastoreclient.factory.class", "com.aliyun.datalake.metastore.hive2.DlfMetaStoreClientFactory") .config("spark.hadoop.dlf.catalog.accessKeyId", dlfCatalogAccessKeyId) .config("spark.hadoop.dlf.catalog.accessKeySecret", dlfCatalogAccessKeySecret) .config("spark.hadoop.dlf.catalog.endpoint", dlfCatalogEndpoint) .config("spark.hadoop.dlf.catalog.id", dlfCatalogId) .config("spark.hadoop.hive.metastore.warehouse.dir", warehouseDir) .enableHiveSupport() .getOrCreate() import spark.sql // create database sql("create database if not exists test_db") // create table sql("create table test_db.test_tbl (key int, value string)") // insert sql("insert into test_db.test_tbl values (0, 'a')") // select sql("select * from test_db.test_tbl").show() // drop table sql("drop table test_db.test_tbl") // drop database sql("drop database test_db") spark.stop() } }需要配置以下参数: sparkMaster:本地运行可配置local[4],集群运行时需配置成yarn-client或yarn-cluster。 dlfCatalogAccessKeyId:访问DLF所需的AccessKey ID。 dlfCatalogAccessKeySecret:访问DLF所需的AccessKey Secret。 dlfCatalogEndpoint:访问DLF所需的Endpoint。 dlfCatalogId:指定的DLF Catalog Id。 warehouseDir:测试数据库的地址。支持以下地址: 本地:例如/tmp/warehouse。 EMR HDFS:例如hdfs://${clusterIP}:9000/xxx,由于该方式要连接EMR集群内的HDFS,需通过SSL-VPN的方式连接VPC,详情请参见客户端远程连接VPC。 OSS:例如oss://,配置参考案例二:Spark连接OSS。 运行main,运行成功后返回以下信息。 +---+-----+ |key|value| +---+-----+ | 0| a| +---+-----+ |
【本文地址】
今日新闻 |
推荐新闻 |